
The “Too Many Tabs” Moment
A hostel room. A laptop glowing late into the night. Tabs stacked with unfamiliar names, Kafka, Spark, Hadoop, each one promising opportunity, each one demanding attention.
For a moment, it feels like stepping into a world where every tool is essential and missing even one could mean falling behind. The landscape of Big Data does not look simple. It looks crowded, fast-moving, and difficult to decode.
This is where most students feel stuck, not because the field is too complex, but because everything seems equally important.
But Big Data is not about learning every tool. It is about understanding which tools matter, why they matter, and where they fit in the bigger picture.
Because once that clarity arrives, the noise disappears, and the path forward becomes far simpler.
The Reality Check: Why Big Data is Your 2026 Survival Kit
In the 2026 job market, big data is no longer an elective. It is your survival kit. Indian tech hubs are no longer just "service centers"; they are the world's data engines. From fintech giants handling millions of real-time UPI transactions to e-commerce firms in Gurugram managing festive-season surges, data is the new oxygen.
Firms are drowning in the "5 Vs" of data:
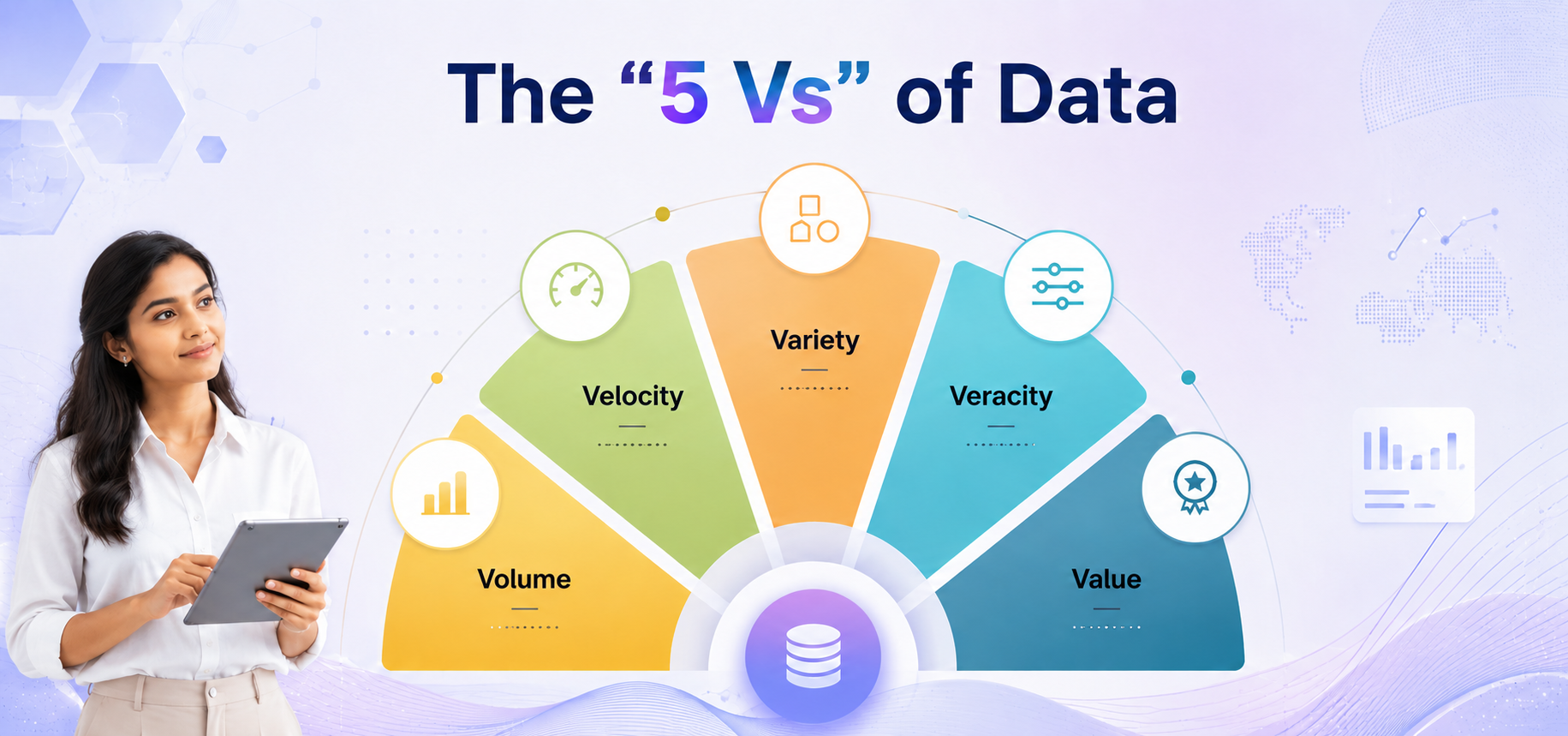
- Volume: Dealing with Petabyte-scale datasets that traditional SQL cannot touch.
- Velocity: Processing data at the speed of a high-frequency stock trade or a social media feed.
- Variety: Managing the chaos of video logs, text, and IoT sensor data simultaneously.
- Veracity: Ensuring data isn't "noisy" or unreliable when high-stakes decisions are on the line.
- Value: The ultimate goal is turning quintillions of raw bytes into actionable business intelligence.
Companies need "lifejackets" graduates who don't just code, but who can architect systems to stay afloat in this information ocean.
The "Mentor’s Secret": Skills Over Tools
Students often fall into the trap of learning to use tools without understanding the underlying logic. A tool is just a hammer; true “data sense” lies in knowing how to build the house. Before working with any framework, the objective must be clear, whether it is storage, real-time analytics, or predictive modeling.
Truth Bombs for Students:
- Depth Beats Breadth: Mastery of two core frameworks is worth more than knowing the names of fifty tools.
- Logic is King: Understanding distributed computing and mathematical complexity matters more than memorizing syntax.
- Order Matters: Learning Spark before you understand SQL is like trying to run a marathon before you can walk.
The Core Toolkit: Tools That Actually Get You Hired
Stop collecting digital badges like they are Pokémon cards in a schoolyard trade. Depth always beats breadth, and the logic of "Defining Objectives" is far more valuable than memorising syntax. You need to understand how data flows and why it fails before you start calling yourself a professional data engineer.

SQL & Python: The Universal Language
Structured Query Language is the bedrock of the entire data world, handling organised information in relational databases. It is the universal tongue spoken by every major enterprise, from local startups to global mass recruiters. Python is the versatile "glue" that binds data engineering to machine learning frameworks like TensorFlow. Its simplicity makes it the weapon of choice for developers at Google and Netflix for complex mathematical computations.
- Real-World Job: The foundation of all data communication. SQL queries the data; Python provides the logic.
- Why You Need It: You cannot talk to a big data framework without these. Python is the most comfortable language for defining tasks in tools like Hive or Spark.
- Beginner Difficulty: Easy
Apache Hadoop: The Grandfather of Big Data
Hadoop is the "Old Guard," but the 3.0 upgrade has brought multiple NameNodes for high availability and better fault tolerance. It uses HDFS to distribute massive datasets across clusters of commodity hardware, teaching us how to scale storage.
- Real-World Job: Large-scale batch processing and archival storage using HDFS.
- Why You Need It: It is the long-standing champion of data lakes. To stand out in 2026, don't just learn the basics; understand that Hadoop 3.0 now supports multiple standby NameNodes for true fault tolerance and high availability.
- Beginner Difficulty: Hard (Complex setup and administration)
Apache Spark: The Speed Demon
Apache Spark is a high-speed engine that processes datasets in-memory, running up to 100 times faster than old batch methods. It is how companies like Uber handle real-time transformations and iterative machine learning at scale.
- Real-World Job: High-speed analytics used by conglomerates like Uber and Airbnb for iterative processing and machine learning.
- Why You Need It: It is 100x faster than traditional MapReduce. This speed comes because it minimises disk I/O by using in-memory processing. If you want to work in real-time analytics, Spark is your primary engine.
- Beginner Difficulty: Moderate
Apache Kafka: The Nervous System
Kafka is a distributed streaming platform designed for high-velocity data feeds from IoT devices or social media. Unlike Spark’s micro-batching, Kafka provides a truly event-driven architecture for moving data with ultra-low latency and high durability.
- Real-World Job: Managing the high-velocity "Velocity" of the 5 Vs. It handles real-time data feeds from IoT devices or high-frequency social media updates.
- Why You Need It: Kafka acts as a distributed streaming platform that ensures low-latency ingestion. It is the backbone of real-time UPI transaction monitoring in India.
- Beginner Difficulty: Moderate
Snowflake or BigQuery: The Cloud Warehouse
Snowflake represents the modern shift to cloud data warehousing, offering "schema-on-read" flexibility that traditional systems lack. It allows teams to query diverse data sources without the rigid, pre-defined structures of the past.
- Real-World Job: Scalable, cloud-based storage that allows firms to move away from expensive on-premise servers.
- Why You Need It: These tools solve the Variety problem of the 5 Vs through "Schema-on-read" flexibility. They allow you to query unstructured data as if it were a neat table.
- Beginner Difficulty: Easy (Managed infrastructure)
Apache Airflow: The Manager
Apache Airflow is the "Glue of the 2026 Stack," responsible for orchestrating and scheduling complex workflows between all other tools. Without orchestration, you aren't building a production-ready system; you're just running disjointed scripts.
- Real-World Job: Orchestrating the complex "pipeline" of data.
- Why You Need It: In a professional environment, you don’t run one script; you run hundreds. Airflow ensures Task B only starts once Task A finishes successfully.
- Beginner Difficulty: Moderate
The Smart Learning Roadmap
-
Your journey begins in Phase 1 with SQL and Python, building the foundation of data interaction and automation. You cannot design a skyscraper on sand, and these two tools are the bedrock of any successful big data career path.
-
Phase 2 moves into storage with Hadoop and HDFS, where you learn the logic of distributed computing. Understanding how Hadoop 3.0 handles multiple NameNodes for high availability is where you build the technical depth that impresses seniors.
-
Phase 3 is where the 15L salaries are made, focusing on high-velocity tools like Spark and Kafka. This is the shift from archival storage to the real-time processing that powers the modern applications students love to use.
-
Phase 4 ties everything together with orchestration via Airflow and cloud warehousing in Snowflake. At this stage, you are no longer just a fresher; you are an architect of production-ready data ecosystems ready for the market.
The "Danger Zone": 4 Mistakes That Kill Careers
-
Tutorial Hell: Watching videos without building. You must get your hands dirty with real-world datasets to understand how systems actually fail.
-
Tool Hoarding: Learning the names of 10 tools at 1% depth. Indian recruiters value "linear scalability", the ability to handle growing workloads with a few tools you know deeply.
-
Ignoring the "Why": You aren't just a coder; you are an architect. In 2026, you must care about Compliance. With India's DPDP (Digital Personal Data Protection) Act, understanding how a tool handles data privacy is as important as its speed.
-
The "Clean Data" Illusion: Real data is messy. Practice using OpenRefine. Don't just learn the name; master its clustering heuristics and reconciliation features to fix inconsistencies that would otherwise crash your pipeline.
Conclusion
The Big Data ecosystem may seem vast and intimidating at first, but the path through it is far more structured than it appears. It comes from clarity, choosing the right tools, understanding their purpose, and building with them consistently.
The industry in 2026 is not searching for students who can recite tool names or chase every new trend. It is looking for problem-solvers who can take raw, unstructured data and transform it into meaningful insights that drive decisions. That capability is not built overnight. It is developed through hands-on practice, experimentation, and the willingness to start even when everything does not feel clear.
Every expert in this field began with a single step, one tool, one project, one attempt that did not work the first time perfectly. What matters is momentum.
The opportunity is not in knowing everything, but in starting early and staying consistent.
Because in a world driven by data, those who learn to shape it are the ones who shape what comes next.